Just a little background. I built a Vortex Manipulator (basically a smart watch that runs on a Teensy3 and does a bit more than a simple clock. I wanted to have notifications from my phone appear on the watch’s screen via Bluetooth, actually BLE. This is about some of the unexpected things I found to get this working.
Structure
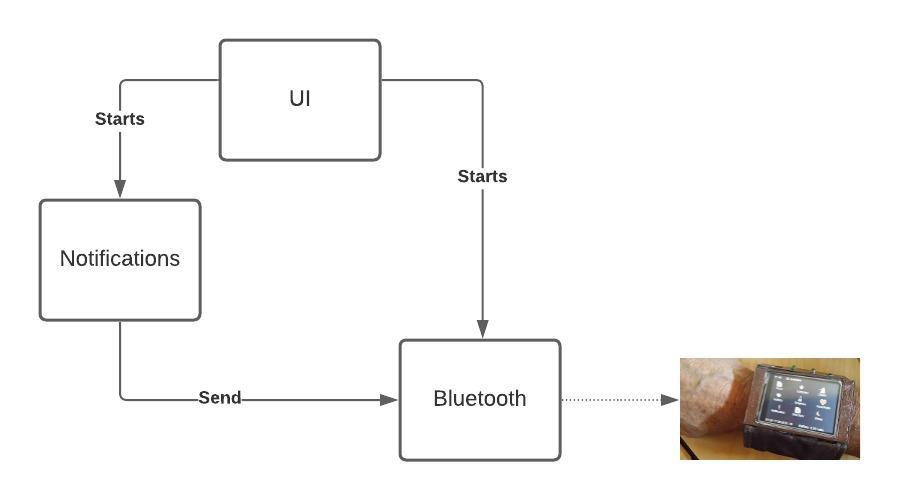
I knew from the start I needed three basic components. The UI, something to capture Notifications and something to handle Bluetooth. The UI could be trivial. I want to be able to start the app, connect to my BLE device and see some confirmation of that connection. Nothing more. So, while there is a lot of richness in the Android Studio for making great UIs, this was not my interest.
It needs to look something like this:
The way to define these relationships int Android Studio is to use the AndroidManifest.xml file.
Mine looks like this.
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.madurasoftware.vmble">
<uses-permission android:name="android.permission.BLUETOOTH" />
<uses-permission android:name="android.permission.BLUETOOTH_ADMIN" />
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
<uses-feature
android:name="android.hardware.bluetooth_le"
android:required="true" />
<application
...
<activity
android:name=".MainActivity"
...
</activity>
<service
android:name="com.madurasoftware.vmble.BLEService"
android:process="com.madurasoftware.vmble.VMServices"
android:label="BluetoothService">
</service>
<service
android:permission="android.permission.BIND_NOTIFICATION_LISTENER_SERVICE"
android:name="com.madurasoftware.vmble.NotificationService"
android:label="NotificationService">
<intent-filter>
<action android:name="android.service.notification.NotificationListenerService" />
</intent-filter>
</service>
</application>I've shortened this a bit to focus on the relvant bits. The full file is here).
The first thing to notice is the permissions. These have to be there in any app that wants to use Bluetooth. With this in place if the phone has Bluettoth turned off when the app starts then Android will ask to turn it on.
In the application section there is the activity which is essentially the UI I mentioned above, and two service sections, one for Bluetooth and one for Notifications.
Now I want to cover what is inside these components.
Notifications.
Notifications, as noted above, are handled by a service. The service is NotificationService and it
extends NotificationListenerService which is supplied by the Android environment. There is not too much
to it. It hears about a notification when its onNotificationPosted() method is called. It filters
the notification (there are a lot of system notifications I don't want to see) and formats the result
suitable for sending, then it passes the notification to the Bluetooth service.
I'll come back to that last bit later on. It's really interesting.
The Notification service is launched from the MainActivity with this code:
val notificationIntent = Intent(context, NotificationService::class.java)
notificationIntent.putExtra(BLEService.CONNECTION,d.address)
context.startService(notificationIntent)There is just a little more to it but that's the main part. We create an intent and launch a service. The service stays running in the background (or seems to). When a notification arrives it handles it.
Now let's go back and look at the code that passes the notification on to the Bluetooth service:
val connectIntent = Intent(this.applicationContext, BLEService::class.java)
connectIntent.putExtra(BLEService.MESSAGE,message)
connectIntent.putExtra(BLEService.CONNECTION,mBluetoothDeviceAddress)
this.applicationContext.startService(connectIntent)Look familiar? Yes, it is just another start service call. I find it odd because I already started the service when I selected the BLE device to connect to. But believe me...
]]>